
I finished building my blog pipeline on a Sunday. By April 21, Danny Sullivan was on stage at Google Search Central Live in Toronto telling the world exactly what I’d accidentally built.
That’s not prediction. That’s arriving at the same conclusion from two different directions — and that convergence is the most interesting signal in the AI content era right now.
Here’s the setup: I run htek.dev, a developer blog I publish using GitHub Copilot CLI agents, Astro 5, MDX, and Vercel. The old publishing workflow — open a text editor, grind out 1,500 words — felt misaligned with how I actually think. Ideas don’t live in structured outlines. They live in car rides, in the middle of a workout, in the moment when two unrelated things click. I’d built complex multi-agent systems to run my household, spec client sites, and govern 50+ AI agents across a production harness. My blog pipeline was still a blank document and a blinking cursor.
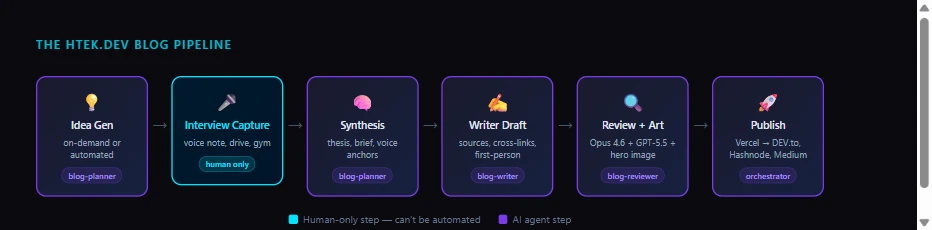
So I built a pipeline. Five stages, each owned by a dedicated AI agent: blog-planner, blog-writer, blog-reviewer, content-illustrator, and a publishing orchestrator that handles GitHub, Vercel, DEV.to, Hashnode, and Medium. The pipeline runs from voice note to published article without me writing a single sentence.
Then Google named the problem I’d solved before I knew I was solving it.
What Commodity Content Actually Is
Google’s definition is direct: commodity content is anything that “could originate from anyone” and adds little unique insight. Non-commodity content is unique, specific, and authentic — rooted in first-hand expertise others can’t replicate. Danny Sullivan introduced this at Google Search Central Live Toronto, April 2026, and Google formalized it in their AI optimization guide on May 15, 2026.
The running store example Sullivan used is worth sitting with. Commodity content: “Top 10 Things to Consider When Buying Running Shoes.” Non-commodity content: “Why This Customer’s Shoes Collapsed After 400 Miles: A Wear Pattern Analysis.” One post exists on a hundred websites. The other can only exist if you examined the actual shoes.
The distinction isn’t about AI versus human authorship. It’s about replaceability. As Nikki Pilkington observed after the Toronto event: “Commodity content is interchangeable by definition. Non-commodity content exists nowhere else, because it comes from something that only happened to you.”
Ann Smarty put it precisely in May 2026: commodity content is anything that can be “repackaged into an AI answer.” If Google AI Overviews or ChatGPT can summarize your post without needing you specifically — the content doesn’t have a moat.
That’s the problem my pipeline was already solving, for reasons that had nothing to do with SEO.
The Pipeline and Why the Interview Is the Crux
The htek.dev blog pipeline runs five stages: idea generation, interview-driven capture, planner synthesis, blog-writer drafting, and review + illustration. Every stage is automated except one — the human interview, which is the only place my actual thinking enters the system. That’s by design.
Idea generation is ambient and on-demand. I can say “I want to write about MeshWire” and the blog-planner agent creates a structured idea with a topic gap analysis. Or I just say “interview me on any pending ideas” — and it does. Ideas arrive without me pausing whatever I’m doing to develop them. I throw the thought out there. The pipeline catches it and holds it until I’m ready.
Once an idea matures into a brief, the planner writes interview questions — the kind that probe how I think, not just what I know. Not “explain MeshWire” but “why does the current approach of connecting agents one by one fail, and what did you see break that made you build something different?” I answer when I have a free moment.
The drive to the gym. A 12-minute commute. This week: the articles for MeshWire’s agent-mesh architecture, the Fat Copilot Extensions pattern, and a raw-CDP performance deep-dive were all interviewed the same week — most of them captured in voice notes during a single gym session. Three blog-ready briefs by 10 AM on a Monday.
The captured interview is the only non-automatable step. The planner synthesizes my answers into a brief: thesis, angle, voice anchors, must-avoid patterns. The blog-writer agent works from that brief — first-person, opinionated, with my actual words and metaphors, cross-referencing related htek.dev articles, citing real sources, passing a dual Claude Opus 4.6 + GPT-5.5 review before any PR is created. The content-illustrator agent generates the hero image and inline visuals.
The article that comes out the other end is grounded in reasoning that only I produced. That’s not a quality claim. It’s a structural claim.
Why Author Bios and AI Disclaimers Don’t Work
Adding an author bio, slapping on “written with AI assistance” disclaimers, or reverse-engineering E-E-A-T signals are all fixes applied to the deliverable. They don’t change what the deliverable contains — which is still commodity output produced by a commodity workflow.
I’ve written about this pattern before in the context of agentic development: code is no longer the asset, workflows are. The same principle holds for content. The blog post isn’t the asset. The process that produced it is. If your process produces content “anyone could write,” your process is the problem — not the byline.
Maria Dykstra’s April 2026 analysis of Sullivan’s framing captures it precisely: AI lowered the production cost of generic content to near zero, so Google’s quality bar moved up to compensate. Commodity content now competes with what any AI can produce in seconds. Commodity content now competes with what any AI tool can produce in seconds. Surface fixes add the appearance of authenticity without the underlying substance. One more Google update and you’re back where you started — because you fixed the symptom, not the cause.
The teams that survive are the ones who redesign around authentic context capture — who ask not “is my content good?” but “does my process produce things that only I could have produced?”
The Scalability of Human Knowledge
This is not an SEO tactic. It’s the scalability of human knowledge — using AI to multiply the throughput of authentic human thinking, not to replace it. The interview-driven pipeline works because of a fundamental mismatch: humans think in conversation, but are expected to produce content in document form.
Give me a question that actually probes how I think and I’ll generate more genuine insight in five minutes than I could produce in an hour staring at a blank editor. The problem with most content workflows is they force you to translate conversational thinking into structured prose before you’ve even captured it — which is where the authentic signal gets lost.
What AI does in this pipeline is draw the lines and glue the edges. I answer interview questions the way I’d answer them to a colleague over lunch — direct, following the thought wherever it goes, making connections I didn’t plan in advance. The blog-writer agent structures that into a coherent article. What comes out is my actual reasoning, not a synthesis of what others have already published.
That’s non-commodity by Google’s own definition: unique (my specific viewpoint), specific (a real pipeline, real tools, real timestamps from this Monday morning), authentic (first-hand knowledge no one else has). Practical Ecommerce noted in June 2026 that this isn’t a new idea — Google has emphasized experience-driven content for years under the E-E-A-T framework. What’s new is AI making the cost of commodity content so low that the distinction has become existential.
The Meta-Loop Is the Point
The article you’re reading right now was produced by the pipeline it describes — voice note on a Monday morning drive, synthesized by the planner, drafted by the blog-writer agent, reviewed by Claude Opus 4.6 and GPT-5.5, illustrated, and submitted via PR. That’s not a footnote. It’s the proof.
This article was produced by the pipeline it describes.
This Monday morning I drove 12 minutes to the gym. I answered five interview questions into a voice note: about Google’s commodity content framing, about why surface-level fixes fail, about what the pipeline actually feels like from the inside, and about what this article shouldn’t say. The planner synthesized a brief. The blog-writer wrote from that brief. A dual Claude Opus 4.6 + GPT-5.5 review ran. The illustrator generated a hero image. A PR was created on GitHub, and I reviewed it before it merged.
That meta-loop is intentional. The thing you’re reading is exactly the kind of content the pipeline is designed to produce — and exactly the kind of content that Google’s generative AI search guidance says should survive the shift.
The side comment from that voice note session is worth capturing: the same interview-driven pattern is emerging across other surfaces — client proposals, video editing scripts, social posts. The pipeline architecture isn’t specific to blog articles. Anywhere humans are expected to produce structured output from unstructured expertise, the interview-first approach is the right architecture. That’s a separate article. It’s already in the pipeline.
Start Refactoring
The Google AI era didn’t change what makes content worth reading. It made the cost of producing worthless content so low that you can’t compete on production speed anymore — you have to compete on something AI can’t replicate in bulk. That’s authentic expertise, captured systematically in a workflow built around human thinking.
I’m not prescribing this pipeline. This is not a how-to.
The point is: the Google AI era didn’t change what makes content worth reading. It made the cost of producing worthless content so low that you can’t compete on production speed anymore. You have to compete on something AI can’t replicate in bulk — authentic expertise, captured systematically.
Look at what your content workflow produces today. Ask whether it could have come from anyone. If the answer is yes, you already know what to refactor. The question isn’t “is my content good?” It’s “does my process produce things that only I could have produced?”
That’s the question I was already asking when I built this pipeline. Google arriving at the same answer — independently, on a different timeline, from a completely different direction — just confirms what happens when you’re solving the right problem.
Start where the workflow is. The content will follow.