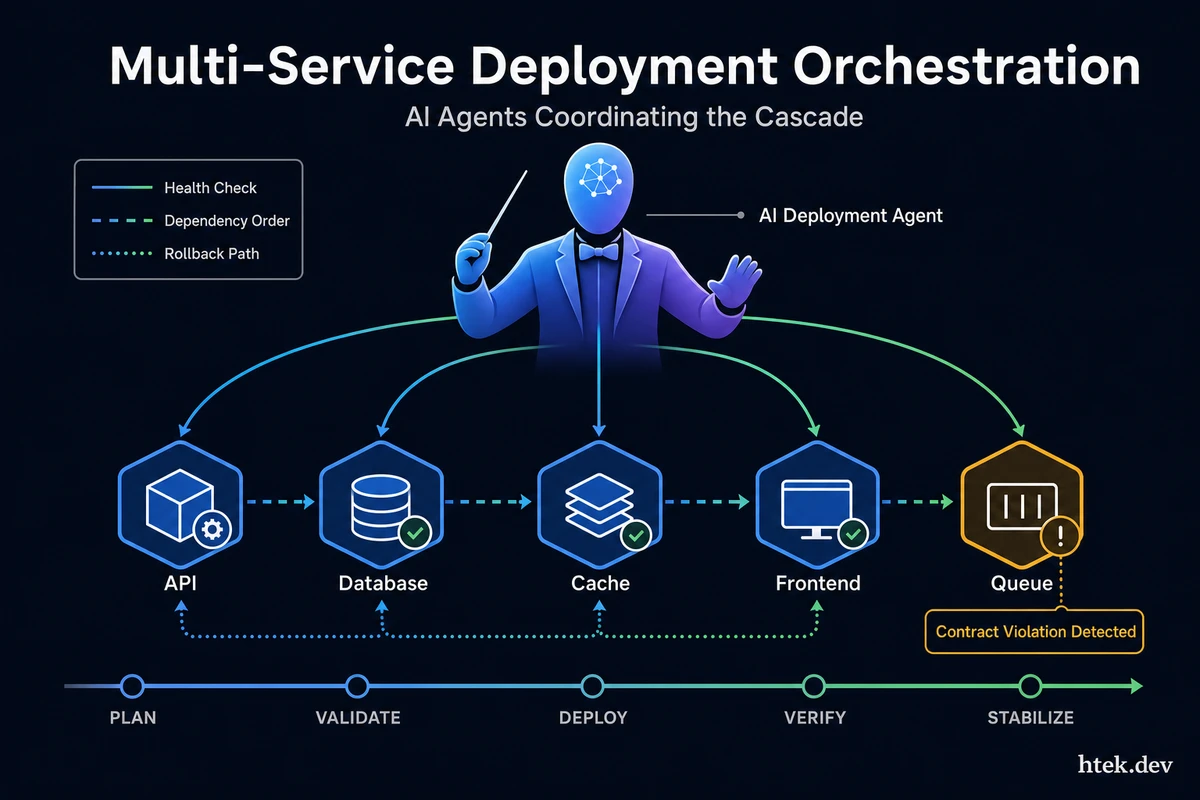
The Cascade Nobody Warned You About
I’ve been in that war room. Three services down, engineers pointing at different dashboards, nobody sure which service failed first or whether rolling back Service A will actually fix Services B and C, or just create a different problem. The incident post-mortem always says something like “deployment coordination gap” — which is a polite way of saying the team didn’t have a plan for what happens when distributed systems fail together.
Multi-service deployments look deceptively simple on paper. You have several services. You deploy them. What’s the problem? The problem is that in production, services aren’t independent units — they’re a web of contracts, dependencies, and timing assumptions. When you deploy them without a coordination strategy, you’re not doing a deployment. You’re doing a controlled chaos experiment and hoping for the best.
The good news: modern tooling, container orchestration, and — increasingly — AI agents have made coordinated multi-service deployments genuinely tractable. Here’s what the real challenges are and what actually works.
Why Multi-Service Deployments Are Hard
 One failed service creates a domino chain — contract violations, migration deadlocks, and queue poisoning cascade through the dependency graph.
One failed service creates a domino chain — contract violations, migration deadlocks, and queue poisoning cascade through the dependency graph.
The core difficulty isn’t technical complexity. It’s invisible coupling.
Most teams think about their service dependencies as a diagram on a whiteboard. In reality, those dependencies are temporal, versioned, and conditional. Service A’s v2 API contract has to be live before Service B can safely switch to it. Your database migration has to complete before the new service version starts accepting writes. Your message queue consumer needs to be running before the producer starts emitting new event types.
Every one of those dependencies has a failure mode. Deploy out of order and you get:
- Contract violations — Service B calls an API endpoint that Service A hasn’t published yet
- Migration deadlocks — Old and new service versions racing against a half-applied schema change
- Message queue poisoning — New event formats arriving before the consumer knows how to handle them
- Rollback fan-out — Rolling back Service A forces rollbacks in Services B, C, and D whether you planned for it or not
The DORA 2024 report found that elite-performing teams deploy on-demand (multiple times daily) while low performers deploy less than once every six months — a 182x gap in deployment frequency. The research identifies deployment automation and coordination practices, not team size or tool choice, as the primary differentiator. The teams shipping daily without incidents have solved the coordination problem. The teams shipping weekly with war rooms haven’t.
The deployment isn’t what fails. The coordination strategy is what fails. Or rather, the absence of one.
Container Orchestration: The Foundation
Before you can coordinate multi-service deployments, you need a runtime that understands service relationships. That’s where container orchestration becomes non-negotiable.
Docker Compose for Local Development
Docker Compose is still the fastest way to model multi-service dependencies in a local environment. The depends_on directive with condition: service_healthy is the piece most teams miss:
services:
api:
build: ./api
depends_on:
database:
condition: service_healthy
cache:
condition: service_healthy
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:3000/health"]
interval: 10s
timeout: 5s
retries: 3
database:
image: postgres:16
healthcheck:
test: ["CMD-SHELL", "pg_isready -U postgres"]
interval: 5s
timeout: 3s
retries: 5
cache:
image: redis:7
healthcheck:
test: ["CMD", "redis-cli", "ping"]
interval: 5s
timeout: 3s
retries: 5Without condition: service_healthy, depends_on only waits for the container to start, not for the service inside it to actually be ready. That’s the difference between a race condition and a guarantee.
Kubernetes Readiness Probes in Production
In production, Kubernetes readiness probes are the connective tissue of a stable multi-service system. A readiness probe tells Kubernetes whether a pod is ready to receive traffic — not just whether it’s alive, but whether it’s operational.
readinessProbe:
httpGet:
path: /health/ready
port: 8080
initialDelaySeconds: 10
periodSeconds: 5
failureThreshold: 3
livenessProbe:
httpGet:
path: /health/live
port: 8080
initialDelaySeconds: 30
periodSeconds: 10
failureThreshold: 5The /health/ready endpoint should be strict: it returns 200 only if all downstream dependencies are reachable. The /health/live endpoint is more permissive — it returns 200 as long as the process isn’t deadlocked. Kubernetes uses readiness to control traffic routing and liveness to decide when to restart a pod.
Most teams conflate them or implement them identically. That’s a mistake. A service can be alive but not ready — and during a deployment, that window matters.
GitHub Actions: Coordinating Deployments in CI/CD
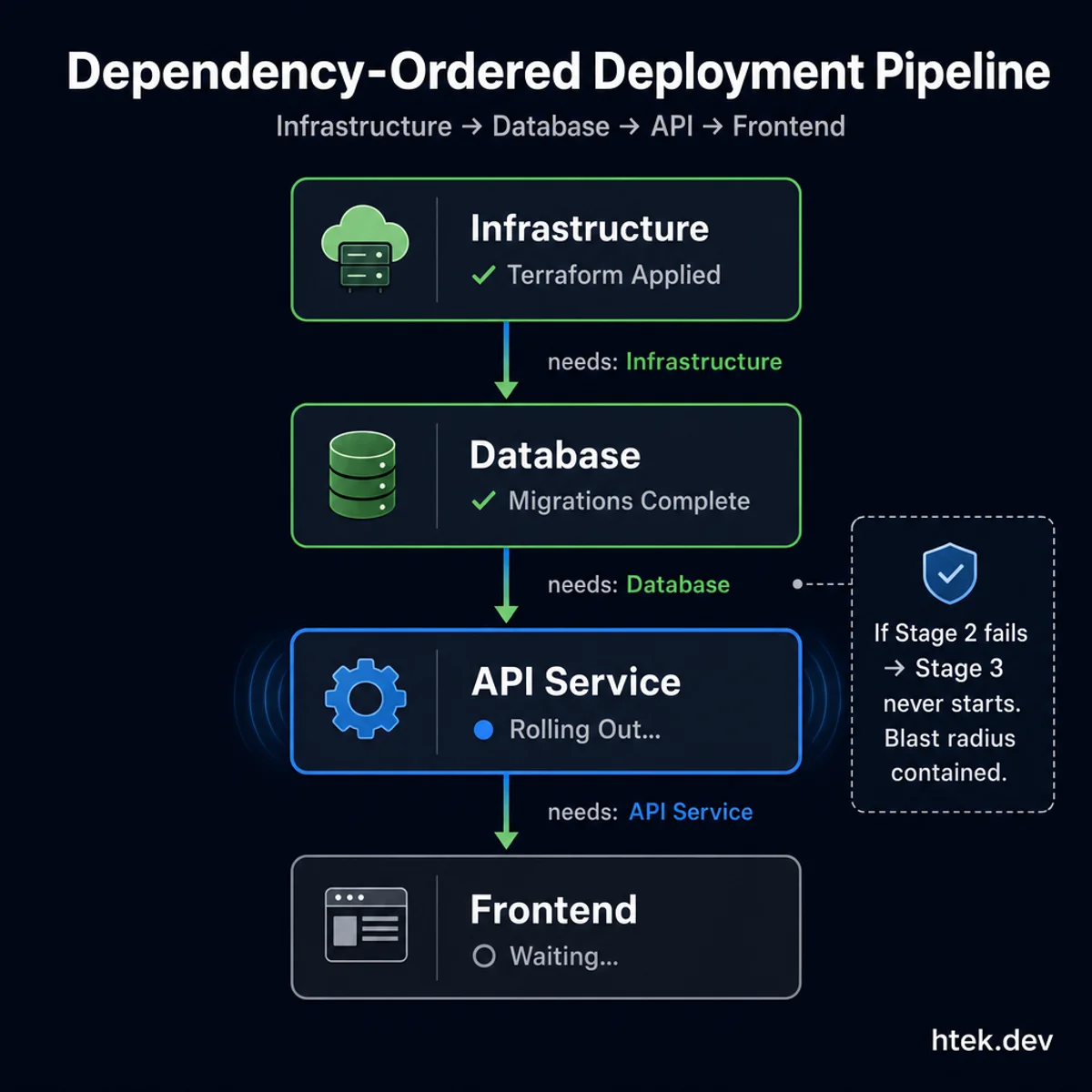 The
The needs keyword creates an explicit dependency graph — if any stage fails, downstream stages never start.
Once you have proper health checks and readiness probes, you can build deployment pipelines that actually respect service dependencies. GitHub Actions multi-job workflows are my preferred tool for this:
jobs:
deploy-infrastructure:
runs-on: ubuntu-latest
steps:
- name: Apply infrastructure changes
run: terraform apply -auto-approve
- name: Wait for infrastructure ready
run: ./scripts/wait-for-infra.sh
deploy-database:
needs: deploy-infrastructure
runs-on: ubuntu-latest
steps:
- name: Run migrations
run: npm run db:migrate
- name: Verify schema version
run: npm run db:verify
deploy-api:
needs: deploy-database
runs-on: ubuntu-latest
steps:
- name: Deploy API service
run: kubectl set image deployment/api api=$IMAGE_TAG
- name: Wait for rollout
run: kubectl rollout status deployment/api --timeout=5m
deploy-frontend:
needs: deploy-api
runs-on: ubuntu-latest
steps:
- name: Deploy frontend
run: kubectl set image deployment/frontend frontend=$IMAGE_TAG
- name: Smoke test
run: ./scripts/smoke-test.shThe needs keyword creates an explicit dependency graph. If deploy-database fails, deploy-api never starts. You get automatic blast radius containment without writing rollback logic for the happy path.
For rollbacks, I pair this with a separate workflow triggered by deployment failure that walks the dependency graph in reverse — a pattern that becomes dramatically simpler when you write for it up front rather than bolting it on after an incident.
Where AI Agents Change the Game
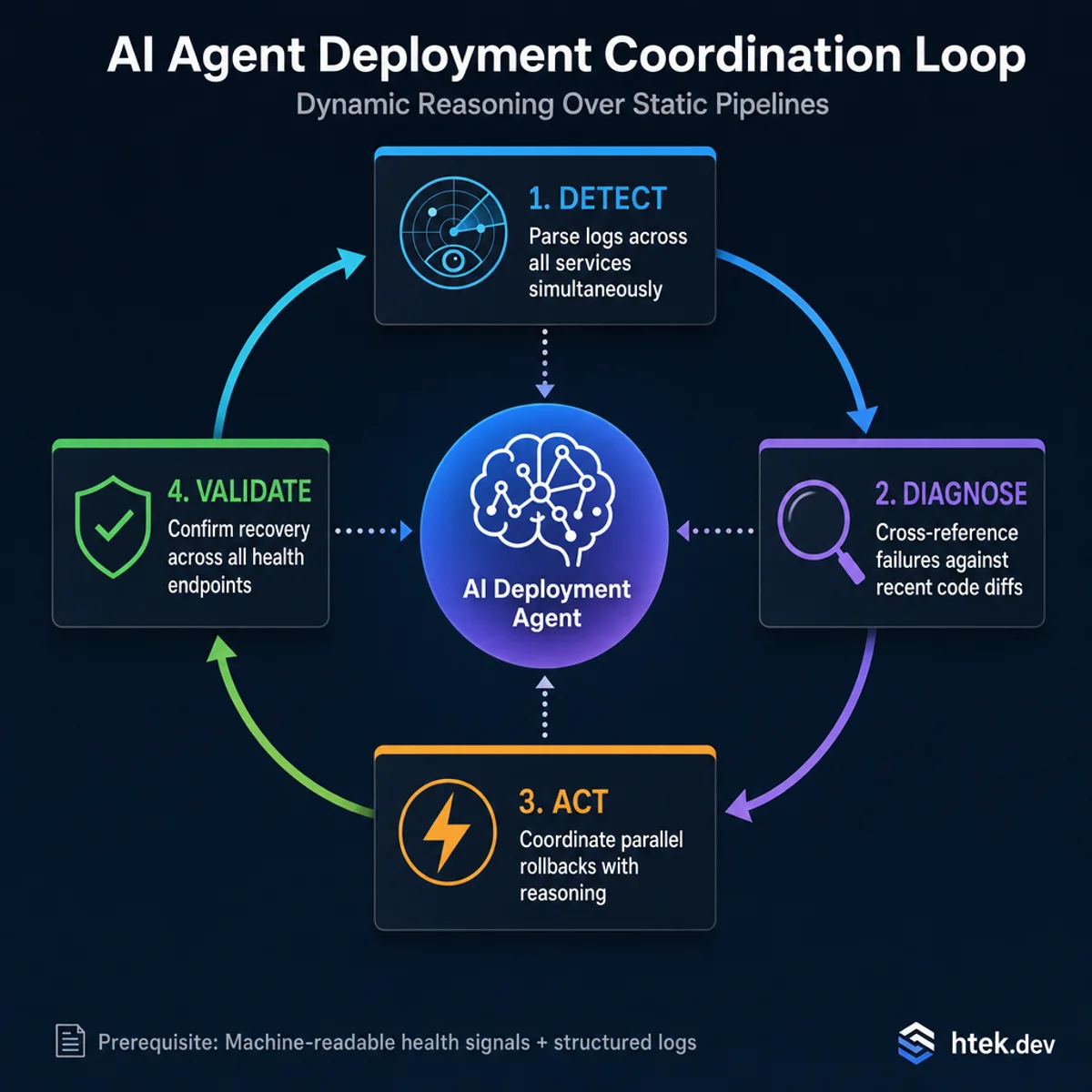 The AI agent feedback loop — dynamic reasoning over deployment state that static pipelines can’t replicate.
The AI agent feedback loop — dynamic reasoning over deployment state that static pipelines can’t replicate.
Here’s where things get genuinely interesting. The patterns above — health checks, readiness probes, dependency-ordered CI/CD — are solid. But they’re static. They assume you wrote the dependency graph correctly, that your health checks cover the right conditions, and that failure modes stay predictable.
In practice, none of those assumptions hold forever.
AI agents are starting to bring dynamic, context-aware reasoning to deployment coordination in ways that static pipelines can’t match. In my work with agentic DevOps patterns, I’ve found that the outer loop of deployment — observability, validation, rollback decisions — is where agents add disproportionate value.
Concretely, an AI agent watching a multi-service deployment can:
- Parse deployment logs across all services simultaneously and identify correlated failure patterns a human would miss scrolling through separate log streams
- Cross-reference health check failures against recent code diffs to distinguish a deployment-caused regression from an infrastructure blip
- Make rollback recommendations with reasoning — not just “Service B is failing” but “Service B’s readiness probe is failing on the
/api/usersendpoint, which matches the contract change in PR #4821 that deployed 8 minutes ago” - Coordinate parallel rollbacks across services that have no hard dependency but are failing for the same upstream reason
This connects directly to what I wrote in self-healing infrastructure with agentic AI. The same feedback loop that makes agents effective at incident response — detect → diagnose → act → validate — maps cleanly onto deployment coordination. The agent isn’t replacing your CI/CD pipeline; it’s reasoning over the output of that pipeline in real time.
The prerequisite, as I covered in agent-proof architecture, is that your infrastructure must be built to support this. Agents need machine-readable health signals, structured deployment logs, and explicitly documented service contracts. If your health checks are a binary “process alive / process dead” and your logs are unstructured strings, the agent doesn’t have enough signal to reason meaningfully.
Agents don’t fix bad observability. They amplify it. Bad observability + agent = confident wrong answers at scale.
Quality context is what makes agents useful — a principle I’ve explored in depth in context engineering for AI development. Your runbooks, dependency maps, and deployment history aren’t just human documentation anymore. They’re agent training data.
The Practical Starting Point
If you’re running multi-service deployments today and feeling the coordination pain, here’s the sequence that actually works:
-
Instrument health checks first. Every service needs a
/health/readyendpoint that reflects real dependency status, not just process status. This is the foundation everything else builds on. -
Map your dependency graph explicitly. Write it down. In a
services.yaml, a README, an ADR — doesn’t matter. The act of writing it reveals assumptions you didn’t know you were making. -
Encode the graph in your CI/CD pipeline. Use
needsin GitHub Actions,depends_onin Docker Compose, or Kubernetes rollout ordering. Make the dependency graph structural, not tribal knowledge. -
Add rollback choreography to the same pipeline. Not as a separate runbook. In the workflow itself, as a failure path that mirrors the deployment path in reverse.
-
Layer in AI observability last. Once you have clean health signals and structured logs, an agent can start reasoning over your deployment state meaningfully. Trying to add this before step 4 is building on sand.
The Bottom Line
Multi-service deployments fail when teams treat coordination as an afterthought. The cascade isn’t bad luck — it’s the predictable result of not encoding your dependency graph anywhere that can enforce it.
Modern tooling gives you the primitives: Docker Compose health conditions for local dev, Kubernetes readiness probes for production, GitHub Actions needs chains for pipeline coordination. AI agents are now adding a layer of dynamic reasoning on top — catching the cross-service failure patterns that static pipelines can’t see and making rollback decisions faster than any on-call engineer at 2 AM.
The teams shipping microservices confidently aren’t doing something exotic. They’re doing the fundamentals with discipline, and they’re increasingly giving agents the observability context to act as a deployment co-pilot. Build the foundation, document the contracts, and the complexity becomes manageable. Skip those steps and you’re back in the war room, staring at dashboards, wondering which service failed first.